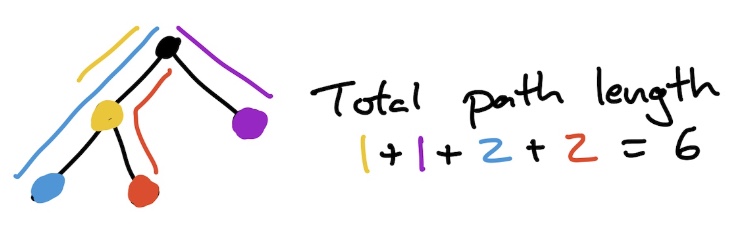Chapter 7: Parameters and Multivariate Generating Functions
#
But whatever I am going to write in mathematics, I believe a major part of it will be “speculation” or “fiction”, going hand in hand with painstaking, down-to-earth work to get hold of the right kind of notions and structures, to work out comprehensive pictures of still misty landscapes.
— Alexander Grothendieck
We do not grow absolutely, chronologically. We grow sometimes in one dimension, and not in another; unevenly. We grow partially. We are relative... We are made up of layers, cells, constellations.
Having developed techniques for the systematic study of combinatorial classes, we now generalize by further classifying objects by the values of certain parameters. Our method of combinatorial constructions can be easily modified to take into account parameters, and we use this approach to derive multivariate generating functions. First, we must discuss some algebraic preliminaries of multivariate formal series.
Just as a combinatorial class has a univariate generating function, a combinatorial class with parameters will have a multivariate generating function. If $D$ is an integral domain then the ring of formal power series with coefficients in $D$ is also an integral domain. Thus, we can define the ring of $d$-variate formal power series inductively by
$$ D[[z_1,\dots,z_d]] = D [[z_1]] [[z_2]] \cdots [[z_d]]. $$
Because we established most of our results for formal power series over arbitrary integral domains, they continue to hold in the multivariate setting.
Example: The elements of $D[[x,y]] = D[[x]] [[y]]$ can be viewed as power series in $y$ whose coefficients are power series in $x.$ For instance, substituting $y=(1+x)y$ into the geometric series
$$ \frac{1}{1-y} = \sum_{n \geq 0}y^n, $$
which is valid as $(1+x)y$ has no constant term as a series in $y,$ gives the expansion
$$ \frac{1}{1-(1+x)y} = \sum_{n \geq 0}(1+x)^ny^n = \sum_{n \geq 0}\left(\sum_{k=0}^n \binom{n}{k}x^k\right)y^n $$
in $D[[x,y]].$
Remark: When the dimension $d$ is understood we write bold symbols for vectors $\mathbf{z} = (z_1,\dots,z_d)$ and use the multi-index notation $\mathbf{z}^\mathbf{i} = z_1^{i_1} \cdots z_d^{i_d}.$
Exercise: Let $\phi: D[[x,y]] \rightarrow D[[y,x]]$ be the map that takes a series in $y$ with coefficients in $D[[x]]$ and returns the series in $x$ with coefficients in $D[[y]]$ obtained by regrouping terms by common powers of $x.$ Prove that $\phi$ is a coefficient preserving ring isomorphism, meaning that $\phi$ is a bijection and for all $F,G \in D[[x,y]],$
$\phi(F+G) = \phi(F)+\phi(G)$
$\phi(FG) = \phi(F)\phi(G)$
$[x^a][y^b]F = [y^b][x^a]\phi(F)$ for all $a,b \in \mathbb{N}.$
This exercise implies that we can write
$$ F(\mathbf{z}) = \sum_{\mathbf{i} \in \mathbb{N}^d} f_\mathbf{i} \mathbf{z}^\mathbf{i} $$
as a series in $D[[\mathbf{z}]]$ without worrying about the order of the variables, and we define
$[\mathbf{z}^\mathbf{i}]F(\mathbf{z}) = f_\mathbf{i} $
for all $\mathbf{i}\in\mathbb{N}^d.$
We also define the ring of iterated Laurent series
$$D((\mathbf{z})) = D((z_1))\cdots((z_d)),$$
however in this definition the order of the variables does matter.
Example: If $F(x,y) = \frac{1}{x+y}$
then in $\mathbb{Q}((x))((y))$ we have
$$ F(x,y) = \frac{1/x}{1+y/x} = \sum_{n \geq 0}\left((-1)^nx^{-n-1}\right)y^n $$
while in $\mathbb{Q}((y))((x))$ we have
$$ F(x,y) = \frac{1/y}{1+x/y} = \sum_{n \geq 0}\left((-1)^ny^{-n-1}\right)x^n, $$
so the coefficients of $F$ depend on the order we give its variables. For instance,
$$[x^{-1}][y^0]F(x,y) = 1 \text{ in } \mathbb{Q}((x))((y))$$
but
$$[y^0][x^{-1}]F(x,y) = 0 \text{ in } \mathbb{Q}((y))((x)).$$
An important subring of $D((\mathbf{z}))$ is the ring of Laurent polynomials $D[\mathbf{z},\overline{\mathbf{z}}]$ which consists of all elements of $D((\mathbf{z}))$ that contain only a finite number of non-zero coefficients (think of them as multivariate polynomials in the $z_j$ and $1/z_j$). Because a Laurent polynomial only has a finite number of terms, the order of the variables defining $D[\mathbf{z},\overline{\mathbf{z}}]$ does not affect coefficient extraction. We thus try to work with Laurent polynomials as much as possible when dealing with series whose terms have negative exponents.
Recall that a combinatorial class is a set of objects together with a weight function such that there are a finite number of objects of any weight. For any $d\in\mathbb{N}$ a combinatorial class with $d$ parameters is a set of objects $\mathcal{C}$ with a weight function $w:\mathcal{C} \rightarrow\mathcal{N}$ and a vector parameter function $\mathbf{p} : \mathcal{C} \rightarrow \mathbb{Z}^d$ such that for all $n\in\mathbb{N}$ only a finite number of objects in $\mathcal{C}$ have weight $n.$
We think of the weight function giving the (non-negative integer) size of an object while the parameter function tracks $d$ (integer valued) parameters. Because we require that $\mathcal{C}$ have a finite number of objects of any size, we do not have to restrict the number of objects that can take various parameter values, since we use them only to refine the finite sets of objects with fixed sizes. The multivariate generating function of a combinatorial class with $d$ parameters $(\mathcal{C},w,\mathbf{p})$ is the formal power series
$$ C(\mathbf{u},z)
= \sum_{\sigma \in C} \mathbf{u}^{\mathbf{p}(\sigma)}z^{w(\sigma)}
= \sum_{n \geq 0}\left(\sum_{\mathbf{i} \in \mathbb{Z}^d} f_{\mathbf{i},n}\mathbf{u}^\mathbf{i}\right)z^n $$
in $\mathbb{Q}[\mathbf{u},\overline{\mathbf{u}}][[z]],$ where
$$f_{\mathbf{i},n} = \# \{\sigma \in \mathcal{C} : \mathbf{p}(\sigma)=\mathbf{i} \text{ and } w(\sigma)=n\}.$$
In particular, for any fixed $n$ only a finite number of coefficients $f_{\mathbf{i},n}$ in the inner sum are non-zero (giving a Laurent polynomial).
Remark: Another potential generalization of the notion of a combinatorial class to the multivariate setting is a collection of objects $\mathcal{C}$ and a vector weight function $w : \mathcal{C} \rightarrow \mathbb{N}^d$ such that the set $\{ \sigma \in \mathcal{C} : w(\sigma) = \mathbf{i} \}$ is finite for all $\mathbf{i} \in \mathbb{N}^d.$ This approach is less useful for our purposes, as the classes we consider have natural notions of size which are privileged among all other parameters that could be tracked.
Example: If $T$ is the class of rooted planar binary trees where the number of leaves (vertices with no children) in a tree $\sigma$ is tracked as a parameter $p(\sigma),$ then we can list the objects of $T$ in increasing size and compute the values of $p$
to determine that the bivariate generating function $T(u,t)$ begins
$$
\begin{aligned}
T(u,z) &= u^0z^0 + u^1z^1 + u^1z^2 + u^1z^2 + u^2z^3 + \cdots \\[+2mm]
&=1 + uz + (2u)z^2 + \cdots
\end{aligned}
$$
We will see how to systematically construct $T(u,z)$ below.
Example: If $B$ is the class of binary strings where the number of zeroes is tracked as a parameter then, since there are $\binom{n}{k}$ binary strings with $k$ zeroes, we have
$$ B(u,z) = \sum_{n \geq 0} \left(\sum_{k=0}^n \binom{n}{k}u^k\right)z^n = \frac{1}{1-(1+u)z}.$$
Exercise: Let $P$ be the class of lattice paths in $\mathbb{Z}^2$ that start at the origin and take steps in $\{(-1,0),(0,-1),(1,0),(0,1)\}$ where the endpoint of a path in $\mathbb{Z}^2$ is tracked as a parameter. Prove that
$$ P(u_1,u_2,z) = \frac{1}{1-(u_1+1/u_1+u_2+1/u_2)z}$$
as an element of $\mathbb{Q}[\mathbf{u},\overline{\mathbf{u}}][[z]].$
For any combinatorial class with parameters we can write
$$ C(\mathbf{u},z) = \sum_{n \geq 0} c_n(\mathbf{u}) z^n, $$
where each $c_n$ is a Laurent polynomial. Because a Laurent polynomial only has a finite number of non-zero terms we can set $\mathbf{u}=\mathbf{1}$ to sum over all possible values of the parameters, ultimately giving
$$ C(\mathbf{1},z) = C(z)$$
where $C(z)$ is the univariate generating function for the class $\mathcal{C}$ with no parameters tracked. This gives a very useful “sanity check” for multivariate generating functions: if you set all parameter variables to $1$ and don’t get the generating function of the underlying class then a mistake was made somewhere in your calculation.
Similarly, if $C(\mathbf{u},z)$ contains no terms of $u_k$ with negative exponent then setting $u_k=0$ in $C(\mathbf{u},z)$ gives the generating function for the objects in $\mathcal{C}$ where the $k$th parameter is zero. This can be useful for enumerating classes of objects where certain behaviours or patterns are forbidden.
If $\mathcal{A}_1,\dots,\mathcal{A}_r$ are combinatorial classes with parameter functions $\mathbf{p}_1,\dots,\mathbf{p}_r$ and $\mathcal{C} = \Phi(\mathcal{A}_1,\dots,\mathcal{A}_r)$ is an admissible construction defining the combinatorial class $\mathcal{C}$ then we say that a parameter function on $\mathcal{C}$ is inherited through the construction if it is defined in terms of $\mathbf{p}_1,\dots,\mathbf{p}_r$ in a natural way (that depends on the construction).
Let $\mathcal{A}$ and $\mathcal{B}$ be combinatorial classes with parameter functions $\mathbf{p}_\mathcal{A}$ and $\mathbf{p}_\mathcal{B}.$
If $\mathcal{C} = \mathcal{A} + \mathcal{B}$ then the inherited parameter function $\mathbf{p}_\mathcal{C}$ on $\mathcal{C}$ is defined by
$$ \mathbf{p}_\mathcal{C}(\sigma)
=
\begin{cases}
\mathbf{p}_\mathcal{A}(\sigma) &\text{ if $\sigma\in\mathcal{A}$} \\
\mathbf{p}_\mathcal{B}(\sigma) &\text{ if $\sigma\in\mathcal{B}$}
\end{cases}
$$
for all $\sigma \in \mathcal{C}.$
If $\mathcal{C} = \mathcal{A} \times \mathcal{B}$ then the inherited parameter function $\mathbf{p}_\mathcal{C}$ on $\mathcal{C}$ is defined by
$$ \mathbf{p}_\mathcal{C}(\alpha,\beta) = \mathbf{p}_\mathcal{A}(\alpha) + \mathbf{p}_\mathcal{B}(\beta) $$
for all $(\alpha,\beta) \in \mathcal{C}.$
If $\mathcal{A}$ has no objects of size $0$ and $\mathcal{C} = \text{SEQ}(\mathcal{A})$ then the inherited parameter function $\mathbf{p}_\mathcal{C}$ on $\mathcal{C}$ is defined by
$$
\mathbf{p}_\mathcal{C}(\alpha_1,\dots,\alpha_r) = \mathbf{p}_\mathcal{A}(\alpha_1) + \cdots + \mathbf{p}_\mathcal{A}(\alpha_r)
$$
for all $(\alpha_1,\dots,\alpha_r) \in \mathcal{C}$
Example: If $\mathcal{A}$ and $\mathcal{B}$ are classes of binary strings then the parameter function tracking the number of zeroes in $\mathcal{A} \times \mathcal{B}$ is inherited from the same parameter function on $\mathcal{A}$ and $\mathcal{B}$ because the number of zeroes in the concatenation of two binary strings $\alpha$ and $\beta$ equals the number of zeroes in $\alpha$ plus the number of zeroes in $\beta.$ The parameter tracking the number of leaves in any type of rooted tree is inherited for a similar reason.
Lemma 1: Let $\mathcal{A}$ and $\mathcal{B}$ be combinatorial classes.
If the parameter function of $\mathcal{C} = \mathcal{A} + \mathcal{B}$ is inherited from the parameter functions of $\mathcal{A}$ and $\mathcal{B}$ then the multivariate generating functions with respect to these parameters satisfies
$$C(\mathbf{u},z) = A(\mathbf{u},z) + B(\mathbf{u},z).$$
If the parameter function of $\mathcal{C} = \mathcal{A} \times \mathcal{B}$ is inherited from the parameter functions of $\mathcal{A}$ and $\mathcal{B}$ then the multivariate generating functions with respect to these parameters satisfies
$$C(\mathbf{u},z) = A(\mathbf{u},z)B(\mathbf{u},z).$$
If $\mathcal{A}$ has no objects of size zero and the parameter function of $\mathcal{C} = \text{SEQ}(\mathcal{A})$ is inherited from the parameter function of $\mathcal{A}$ then the multivariate generating functions with respect to these parameters satisfies
$$C(\mathbf{u},z) = \frac{1}{1-A(\mathbf{u},z)}.$$
Exercise: Prove Lemma 1 by generalizing the arguments used in Chapter 5 to relate the generating functions of combinatorial classes under the combinatorial sum, product, and sequence.
To compute generating functions using constructions, it is most useful to introduce new parameterized neutral classes $\mu_1,\mu_2,\dots$ that have size zero but contribute to the parameters being tracked. The parameterized specifications with these special types of neutral elements immediately give equations satisfied by the multivariate generating functions of classes with inherited parameters.
Example: Let $\mathcal{B}$ be the class of binary strings enumerated by size and the number of zeroes they contain. Then
$$ \mathcal{B} = \text{SEQ}(\mathcal{Z}_0 \times \mu + \mathcal{Z}_1)$$
where $\mathcal{Z}_0$ and $\mathcal{Z}_1$ are atomic classes corresponding to the digits $0$ and $1,$ respectively, and $\mu$ is a neutral class marking when a single $0$ occurs. The atomic classes have generating functions equal to $z$ while the neutral class $\mu$ has generating function $u,$ so this parameterized specification directly gives the bivariate generating function
$$ B(u,z) = \frac{1}{1-(uz+z)} = \frac{1}{1-(1+u)z}$$
already seen above.
Remark: The term $\mathcal{Z}_0 \times \mu$ appearing in the last example can be viewed as “attaching” the sizeless marker $\mu$ to the digit $0.$ Atomic classes are always viewed as being “parameterless” with the accounting of parameters delegated to parameterized neutral classes.
Example: Find an algebraic equation satisfied by the bivariate generating function of planar rooted binary trees enumerated by size and number of leaves.
Click for Answer
Our usual specification
$$\mathcal{T} = \epsilon + \mathcal{Z} \times \mathcal{T}^2$$
for the class of planar rooted binary trees does not easily lend itself to tracking leaves, because it is hard to see which terms correspond to leaves. Instead, we can use the specification
$$ \mathcal{N}
= \underbrace{\mathcal{Z}}_\text{no children}
+\;
\underbrace{\mathcal{Z}\times\epsilon\times\mathcal{N}}_\text{only right child}
\;+\;
\underbrace{\mathcal{Z}\times\mathcal{N}\times\epsilon}_\text{only left child}
\;+\;
\underbrace{\mathcal{Z}\times\mathcal{N}^2}_\text{two children}
$$
for the class $\mathcal{N}$ of non-empty rooted planar binary trees that decomposes a tree in terms of its nonempty subtrees. A leaf is a vertex with no children, so we have the parameterized specification
$$\mathcal{N} = \mathcal{Z}\times\mu
\;+\;\mathcal{Z}\times\epsilon\times\mathcal{N}
\;+\;\mathcal{Z}\times\mathcal{N}\times\epsilon
\;+\;\mathcal{Z}\times\mathcal{N}^2
$$
where $\mu$ is a neutral class marking when a leaf occurs. This specification immediately gives the algebraic equation
$$ N(u,z) = uz + 2zN(u,z) + zN(u,z)^2. $$
If one wants to include the empty binary tree in the class under consideration then the identity $T(u,z) = N(u,z) + 1$ implies
$$ T(u,z) - 1 = uz + 2z\left(T(u,z)-1\right) + z\left(T(u,z)-1\right)^2. $$
We also note that the quadratic formula gives the single power series solution
$$
\begin{aligned}
N(u,z) &= \frac{1-2z-\sqrt{1-4z+(1-u)4z^2}}{2z} \\[+4mm]
&= uz + (2u)z^2 + (u^2+4u)z^3 + \cdots
\end{aligned}$$
to the algebraic equation satisfied by $N(u,z).$ As expected, we can recover the generating function
$$N(1,z) = \frac{1-\sqrt{1-4z}}{2z}-1$$
for non-empty rooted planar binary trees, and the generating function
$$N(0,z) = \frac{1-2z - \sqrt{(1-2z)^2}}{2z}=0$$
for the number of nonempty binary trees with no leaves (there are none!).
Multivariate generating functions find great application in probability theory. Generalizing from the univariate setting, the formal partial derivative (with respect to the variable $u$) of a bivariate generating series
$$C(u,z) = \sum_{n \geq 0}\left(\sum_{k \in \mathbb{Z}}c_{k,n}u^k\right)z^n$$
in $\mathbb{Z}[u,\overline{u}][[z]]$ is the series
$$ \frac{d}{du}C(u,z) = C_u(u,z) = \sum_{n \geq 0}\left( \sum_{k \in \mathbb{Z}} k c_{k,n} u^{k-1} \right)z^n. $$
The expected value or average value of a one-dimensional parameter $p:\mathcal{C}\rightarrow\mathbb{Z}$ on the objects of size $n$ is defined as
$$
\begin{aligned}
\mathbb{E}_n[p]
&:= \sum_{k \in \mathbb{Z}} k \cdot \left[\text{probability that $p(\sigma)=k$ when $|\sigma|=n$}\right] \\[+2mm]
&= \sum_{k \in \mathbb{Z}} k \cdot \left[\frac{\text{$\#$ objects with $|\sigma|=n$ and $p(\sigma)=k$}}{\text{$\#$ objects with $|\sigma|=n$}}\right] \\[+2mm]
&= \sum_{k \in \mathbb{Z}} k \; \frac{c_{k,n}}{c_n}
\end{aligned}
$$
when this series exists, where $c_n$ denotes the total number of objects of size $n$ in $\mathcal{C}.$
Proposition 1: For all $n \in \mathbb{N},$
$$ \mathbb{E}_n[p] = \frac{[z^n]C_u(1,z)}{[z^n]C(1,z)}. $$
Proof of Proposition 1
The definition of the formal partial derivative implies
$$[z^n]C_u(u,z) = \sum_{k \in \mathbb{Z}} kc_{k,n} u^{k-1},$$
so setting $u=1$ gives
$$[z^n]C_u(1,z) = \sum_{k \in \mathbb{Z}} kc_{k,n}.$$
The result follows as $[z^n]C(1,z) = C(z) = c_n$ is independent of $k$ and can thus be brought inside this series.
Very Useful Remark: Because our definitions of formal derivatives match the behaviour of derivatives for functions, the formal derivative of any rational function or generalized binomial power $(1+z)^\alpha$ matches its calculus derivative. Just like the univariate formal derivative, the formal partial derivative also satisfies the product and chain rules.
Remark: The coefficient $[z^n]C_u(1,z)$ describes the total value of a parameter among all objects in the class $\mathcal{C}$ of size $n.$
Example: Find the average number of zeroes among the binary strings of length $n.$
Click for Answer
We have already seen the bivariate generating function
$$ B(u,z) = \frac{1}{1-(u+1)z} $$
enumerating binary strings by size and number of zeroes. Thus,
$$ B_u(1,z) = \left.\frac{z}{(1-(u+1)z)^2}\right|_{u=1} = \frac{z}{(1-2z)^2}.$$
The Negative Binomial Theorem implies that there are
$$ [z^n] \frac{z}{(1-2z)^2} = [z^{n-1}] (1-2z)^{-2} = 2^{n-1}\binom{n}{n-1} = n2^{n-1}$$
zeroes among all binary strings of length $n,$ so the average number of zeroes among the binary strings of length $n$ is
$$ \frac{[z^n] \frac{z}{(1-2z)^2}}{[z^n]\frac{1}{1-2z}} = \frac{n2^{n-1}}{2^n} = \frac{n}{2}.$$
This makes intuitive sense, as each of the $n$ digits can be either a $0$ or a $1.$
Example: Find the average number of ones among the compositions of size $n.$
Click for Answer
Let $\mathcal{C}$ be the class of compositions. Our first goal is to determine the bivariate generating function enumerating $\mathcal{C}$ by size and number of ones.
We have previously used the specification
$$\mathcal{C} = \text{SEQ}\left(\text{SEQ}_{\geq 1}(\mathcal{Z})\right)$$
to enumerate compositions, however this construction makes it difficult to track our parameter. Instead, we separate out the ones in a composition using the specification
$$\mathcal{C} = \text{SEQ}\left(\mathcal{Z} + \text{SEQ}_{\geq 2}(\mathcal{Z})\right),$$
which decomposes a composition as a sequence of elements that are either $1$ or a positive integer greater than $1.$ If $\mu$ is a neutral class marking when a single $1$ occurs then we have the parameterized specification
$$\mathcal{C} = \text{SEQ}\left(\mathcal{Z} \times \mu + \text{SEQ}_{\geq 2}(\mathcal{Z})\right),$$
giving the bivariate generating function
$$ C(u,z)
= \frac{1}{1-\left(uz + \frac{z^2}{1-z}\right)}
= \frac{1-z}{(1-z)(1-uz) - z^2}. $$
As seen previously, for $n \geq 1$ we have
$$ [z^n]C(1,z) = [z^n]\frac{1-z}{1-2z} = 2^{n-1}. $$
Furthermore,
$$
C_u(1,z) = \left.\frac{(1-z)^2z}{\left((1-z)(1-uz)-z^2\right)^2}\right|_{u=1} = \frac{(1-z)^2z}{(1-2z)^2}
$$
so
$$
\begin{aligned} [z^n]C_u(1,z) =
[z^{n-1}] (1-2z)^{-2} &- 2[z^{n-2}] (1-2z)^{-2} \\[+2mm]
&+[z^{n-3}] (1-2z)^{-2}.
\end{aligned}
$$
The negative binomial theorem implies
$$[z^k] (1-2z)^{-2} = 2^k\binom{k+1}{k} = 2^k(k+1)$$
for all $k \geq 0,$ so if $n \geq 3$ then
$$
\begin{aligned}
[z^n]C_u(1,z) &= 2^{n-1}n - 2^{n-1}(n-1) + 2^{n-3}(n-2) \\
&= 2^{n-1} + 2^{n-3}n - 2^{n-2} \\
&= 2^{n-2} + 2^{n-3}n.
\end{aligned}
$$
The average number of ones among the compositions of size $n$ is thus
$$ \frac{2^{n-2}+2^{n-3}n}{2^{n-1}} = \frac{2+n}{4}$$
if $n \geq 3,$ while the average is $0$ is $n=0$ and the average is $1$ if $n=1$ or $n=2.$
The expected value of a parameter can be viewed as one of its most basic statistical properties. More advanced arguments, using tools from analysis and probability theory, can be used to derive limit theorems for parameters from bivariate generating functions. For instance, many natural parameters on combinatorial classes scale to normal distributions as the size of the objects approaches infinity.
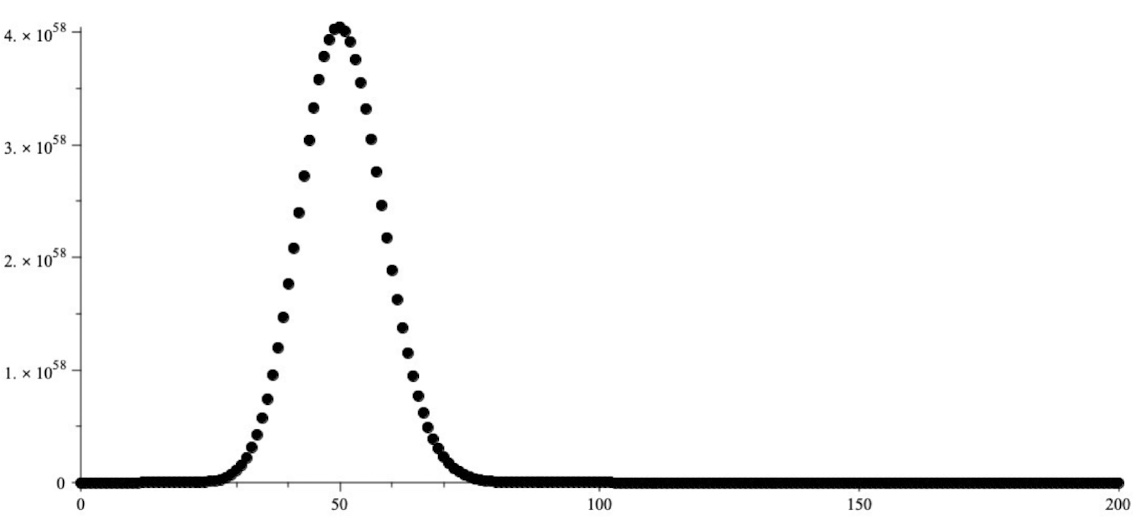
Figure:
A plot of the number of compositions of size $200$ counted by the number of ones they contain ($x$-axis), which is close to a normal distribution. Note the peak near $50,$ the closest integer to the expected value $(200+2)/4.$
Because we established LIFT for any series with coefficients in an integral domain, it can be directly applied to extract coefficients from bivariate series. LIFT is particularly useful when combined with the next exercise, which follows directly from our definitions.
Exercise: Prove that
$$ [z^n]\frac{d}{du}C(u,z) = \frac{d}{du}[z^n]C(u,z) $$
for any integral domain $D$ and series $C(u,z) \in D[u,\overline{u}][[z]].$
Example: Find the average number of leaves among the rooted planar binary trees of size $n.$
Click for Answer
Above we derived the algebraic equation
$$ N(u,z) = uz + 2zN(u,z) + zN(u,z)^2 $$
for the bivariate generating function $N(u,z)$ enumerating rooted planar binary trees by size and number of leaves. Thus, we have
$$ z = \frac{N(u,z)}{u + 2N(u,z) + N(u,z)^2} = \frac{N(u,z)}{G(N(u,z))}$$
where $G(t) = u + 2t + t^2$ (note that $u$ is reserved for the variable tracking leaves and $t$ will be used for LIFT). The constant $G(0)=u$ is invertible in $\mathbb{Q}[u,\overline{u}]$ so the last exercise, LIFT, and the binomial theorem imply
$$
\begin{aligned}
\left.[z^n]\frac{d}{du}N(u,z) \right|_{u=1}
&= \left. \frac{d}{du} [z^n]N(u,z)\right|_{u=1} \\[+2mm]
&= \left. \frac{d}{du} \left(\frac{1}{n} \; [t^{n-1}] (u+2t+t^2)^n\right) \right|_{u=1} \\[+2mm]
&= \left. [t^{n-1}] \left(\frac{1}{n} \; \frac{d}{du} (u+2t+t^2)^n \right)\right|_{u=1} \\[+2mm]
&= \left. [t^{n-1}] (u+2t+t^2)^{n-1} \right|_{u=1} \\[+2mm]
&= [t^{n-1}] (1+2t+t^2)^{n-1} \\[+2mm]
&= [t^{n-1}] (1+t)^{2(n-1)} \\[+2mm]
&= \binom{2n-2}{n-1}
\end{aligned}
$$
for all $n\geq1.$ Thus, since there are $\frac{1}{n+1}\binom{2n}{n}$ rooted planar binary trees of size $n,$ the average number of leaves among the trees of size $n \geq 1$ is
$$
\begin{aligned}
\frac{\binom{2n-2}{n-1}}{\frac{1}{n+1}\binom{2n}{n}}
&= (n+1) \; \frac{(2n-2)!}{(2n)!} \cdot \frac{n!}{(n-1)!} \cdot \frac{n!}{(n-1)!} \\[+2mm]
&= \frac{n(n+1)}{2(2n-1)}.
\end{aligned}
$$
Note that as $n\rightarrow\infty$ this average grows like $n/4,$ so approximately one quarter of the nodes in random binary trees of large sizes are leaves.
Higher order statistical properties of parameters can be deduced from higher order derivatives.
Exercise: The variance of a univariate combinatorial parameter $p:\mathcal{C}\rightarrow\mathbb{Z}$ on the objects of size $n$ in a combinatorial class $\mathcal{C}$ is
$$ \text{Var}_n[p] = \mathbb{E}_n\left[p^2\right] - \mathbb{E}_n[p]^2 $$
(the first term is the expected value of the parameter function $p^2$ while the second is the square of the expected value of $p$). Prove that
$$ \mathbb{E}_n\left[p^2\right] = \frac{[z^n]\left(C_{uu}(1,z) + C_u(1,z)\right)}{[z^n]C(1,z)}, $$
where $C(u,z)$ is the bivariate generating function enumerating $\mathcal{C}$ in terms of size and the parameter $p,$ and $C_{uu}$ is the second partial derivative of $C$ with respect to $u.$ Conclude that
$$ \text{Var}_n[p] = \frac{[z^n]\left(C_{uu}(1,z) + C_u(1,z)\right)}{[z^n]C(1,z)} - \left(\frac{[z^n]C_u(1,z)}{[z^n]C(1,z)}\right)^2. $$
Exercise: Find the variance for the number of zeroes among the binary strings of length $n.$
The variance of a parameter is a measure of how close the parameter lies to its expected value among all objects of size $n.$ The following classical inequality can be found in any introductory probability textbook.
Chebyshev’s inequality: If $\mu$ and $\nu$ denote the expected value and variance of a parameter $p$ on the objects of size $n$ and $\nu > 0$ then for any $k>0$ the probability that a (uniformly) randomly selected object $\sigma$ of size $n$ satisfies $|p(\sigma) - \mu| \geq k$ is at most $\nu/k^2.$
Corollary: Let $p$ be a univariate combinatorial parameter on a combinatorial class $\mathcal{C}.$ If $\mathbb{E}_n[p]^2 \neq 0$ for all sufficiently large $n$ and
$$ \lim_{n \rightarrow \infty} \left(\frac{\text{Var}_n[p]}{\mathbb{E}_n[p]^2}\right) = 0 $$
then for any fixed $\epsilon > 0$ the probability that a (uniformly) randomly selected object $\sigma \in \mathcal{C}$ of size $n$ satisfies
$$ (1-\epsilon) \mathbb{E}_n[p] \leq p(\sigma) \leq (1+\epsilon)\mathbb{E}_n[p] $$
goes to $1$ as $n\rightarrow\infty.$
Exercise: Prove that the parameter counting the number of zeroes in a binary string is concentrated around its expected value.
Problem 1: Find the average number of summands among all compositions of size $n.$
Problem 2: Fix a positive integer $r$ and for any $n\in\mathbb{N}$ let $a_r(n)$ be the average number of times that $r$ appears among the compositions of size $n.$ Prove that the ratio of $a_r(n)$ and $n/2^{r+1}$ approaches $1$ as $n\rightarrow\infty.$
Problem 3: Find the average number of leaves among all rooted planar ternary trees of size $n$ (where each node has three, possibly empty, ordered subtrees as children).
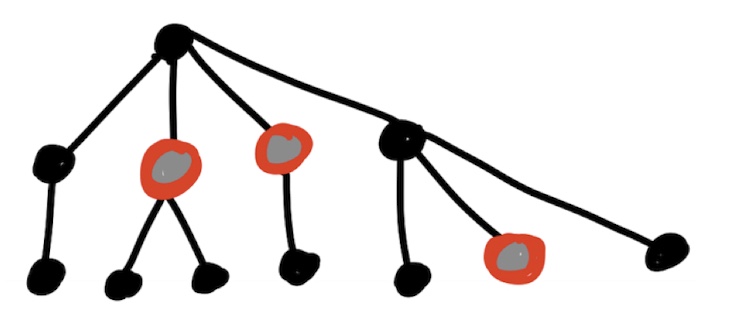
Problem 4: A middle child in a rooted planar tree is a non-root node that is neither the leftmost child nor the rightmost child of its parent. For instance, the following tree has three middle children which are highlighted.
Determine the average of the number of middle children among the rooted planar trees on $n$ nodes.
Problem 5: Find the bivariate generating function for binary strings with no consecutive zeroes enumerated by size and number of zeroes.
Problem 6:(a) Generalize a proof of the binomial theorem to prove the trinomial theorem:
$$ (x+y+z)^n = \sum_{\substack{a+b+c=n \\ a,b,c \geq 0}}\binom{n}{a,b,c}x^ay^bz^c$$
where
$$ \binom{n}{a,b,c} = \frac{n!}{a!b!c!}.$$
(b) Use LIFT and part (a) to prove that, under suitable conditions on $n,a,b,$ and $c,$ there are
$$ \frac{2^b}{n}\binom{n}{a,b,c} $$
rooted binary trees with $a$ leaves, $b$ vertices of degree one, and $c$ vertices of degree two. What are the conditions on $a,b,c,$ and $n$ for this formula to hold?
Problem 7: Recall that a Motzkin path of length $n$ is a sequence of $n$ up steps $(1,1),$ horizontal steps $(1,0),$ and down steps $(1,-1)$ that starts at $(0,0),$ ends at $(n,0)$ and never goes below the $x$-axis. Find the average number of horizontal steps among the Motzkin paths of length $n.$
Problem 8: Recall that a Dyck path of length $n$ is a sequence of $n$ up steps $(1,1)$ and down steps $(1,-1)$ that starts at $(0,0),$ ends at $(n,0)$ and never goes below the $x$-axis. A peak in a Dyck path is an occurrence of an up step immediately followed by a down step. Find the average number of peaks among the Dyck paths of length $n.$
Problem 9: Find the average number of times a Dyck path of length $n$ touches the $x$-axis.
Problem 10: The length of a path in a tree is the number of edges between the endpoints in the path. The total path length of a tree is the sum of all the distances from the vertices in the tree to the root (the distance from the root to itself is zero).
Let $B$ be the class of complete rooted planar binary trees, defined by the specification $B = Z + Z \times B^2.$
(a) Show that the bivariate generating function $B(u,z)$ tracking the size and total path length of a tree satisfies the equation
$$B(u,z) = z + zB(u,uz)^2.$$
Hint: In this case it is probably easier to start from the definition of $B(u,x)$ than it is to use a construction with a tracking parameter.
(b) Prove that the expected total path length among all complete rooted planar binary trees of odd size $n$ approaches $\sqrt{\pi n^3/2}$ as $n\rightarrow\infty.$ You may use without proof that $\binom{2n}{n} \sim 4^n/\sqrt{\pi n}$ as $n\rightarrow\infty$ if needed.
Remark on Applications of Problem 10
Since there are $n$ nodes in a binary tree of size $n,$ Problem 10(b) implies that the average path length in a random binary tree of large size $n$ is approximately $\sqrt{\pi n/2}.$ This allows one to say things about the average case complexity of search algorithms operating on binary trees (average path length also tracks things like the average number of ancestors in phylogenetic trees used in evolutionary models). Note that binary search trees, which appear more frequently in computer science, are a different model – the fact that the average path length in a random binary search tree of size $n$ grows like a constant times $\log n$ instead of a constant times $\sqrt{n}$ shows that binary search trees are a great data structure for storing and retrieving data (and hence why they appear so frequently).